网安导实验二教程
网安导实验二:“GDB 使用”的教程
网安导大概是我第一次也是最后一次用 GDB。

话不多说,直接上教程。
什么是 GDB,为什么是 GDB?
GDB 是 GNU Debugger 的缩写,是一个强大的程序调试工具。GDB 可以帮助程序员在程序运行时检查程序的内部状态,查看变量的值,查看函数的调用栈,查看寄存器的值等等。
用 GDB 的原因很简单,因为我们的实验要求使用 GDB
调试程序。GDB
提供了多语言、跨平台的支持,并且其功能比你现在想象的应该还要强大的多。
VS Code 的 GDB 调试
VS Code 可以通过 DAP 协议调用 GDB 调试 C 和 C++ 程序,这种界面化的方式简单清晰,非常适合有源码的情况下调试程序。
正常来说安装了 Code Runner 插件可以直接在右上角启动调试,并且不需要额外配置。
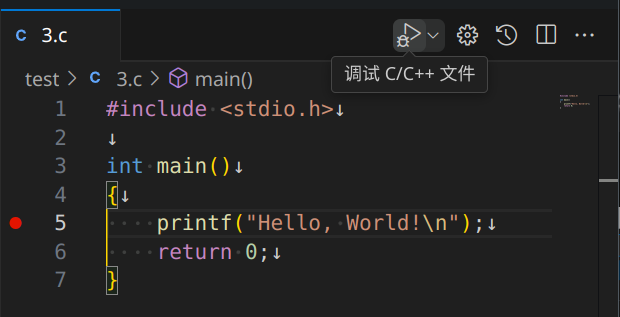
在 VS Code 编辑区,左侧行号前若鼠标悬停会出现淡色红点,点击即可设置断点。断点,故名思义,就是调试程序在运行至这行代码时会暂停,方便我们检查程序的运行状态。
调试开始后,VS Code 编辑器上方会出现调试工具栏,包括以下功能按钮:
- 继续(Continue):继续运行程序,直到遇到下一个断点。
- 逐过程(Step Over):执行当前行代码,但不进入函数内部。
- 单步调试(Step Into):逐步执行当前行代码,并进入函数内部。
- 单步跳出(Step Out):执行完当前函数的剩余代码,并返回到调用该函数的地方。
- 重启(Restart):重新启动调试会话。
- 停止(Stop):停止调试会话。
这些按钮可以帮助你在调试过程中更好地控制程序的执行流程。
VS Code 最左侧侧边栏中的调试视图中提供了一些调试信息,包括:
- 变量(Variables):显示当前作用域内的变量及其值。
- Locals:显示当前函数内的局部变量。
- Registers:显示 CPU 寄存器的值(下面会详细介绍)。
- 堆栈(Call Stack):显示当前函数调用栈。
- 监视(Watch):可以添加需要监视的变量,方便查看其值的变化。
- 断点(Breakpoints):显示当前设置的断点。
命令行下的 GDB 调试
在命令行下使用 GDB 调试程序,需要先编译程序时加上 -g
选项,以便生成调试信息。例如:
1 | gcc -g -o program program.c |
然后使用 GDB 调试程序:
1 | gdb program |
启动和过程与 VS Code 一样,不过是将所有操作变为命令行操作。
GDB 命令速查表
提供速查表:
断点(Breakpoints)
| 命令 | 描述 |
|---|---|
break 或 b |
设置一个断点 |
break <line_number> |
在特定行号设置断点 |
break <function_name> |
在特定函数设置断点 |
break <file_name>:<line_number> |
在特定文件的特定行号设置断点 |
break <file_name>:<function_name> |
在特定文件的特定函数设置断点 |
delete 或 d |
删除所有断点 |
delete <breakpoint_number> |
删除特定断点 |
disable b <breakpoint_number> |
禁用特定断点 |
enable b <breakpoint_number> |
启用特定断点 |
info b |
列出所有断点 |
运行(Running)
| 命令 | 描述 |
|---|---|
run 或 r |
运行程序 |
run <args> |
带参数运行程序 |
run < <input_file> |
从文件输入运行程序 |
单步执行(Stepping)
| 命令 | 描述 |
|---|---|
next 或 n |
单步执行(不进入函数) |
step 或 s |
单步执行(进入函数) |
finish |
执行到当前函数结束 |
打印(Printing)
| 命令 | 描述 |
|---|---|
print 或 p |
打印变量值 |
print <expression> |
打印表达式的值 |
display |
每次程序停止时打印变量值 |
undisplay |
停止打印变量值 |
x |
检查内存 |
x/<n><format><size> |
以特定格式和大小检查内存 |
格式说明符(Format Specifiers)
| 格式 | 描述 |
|---|---|
x |
十六进制 |
d |
十进制 |
u |
无符号十进制 |
o |
八进制 |
t |
二进制 |
f |
浮点数 |
a |
地址 |
c |
字符 |
s |
字符串 |
i |
指令 |
m |
十六进制带 ASCII |
大小说明符(Size Specifiers)
| 大小 | 描述 |
|---|---|
b |
字节 |
h |
半字(2 字节) |
w |
字(4 字节) |
g |
巨字(8 字节) |
寄存器(Registers)
| 命令 | 描述 |
|---|---|
info registers |
列出所有寄存器 |
info registers <register> |
列出特定寄存器 |
堆栈(Stack)
| 命令 | 描述 |
|---|---|
backtrace 或 bt |
打印当前堆栈跟踪 |
frame |
打印当前帧 |
frame <frame_number> |
选择特定帧 |
up |
向上移动堆栈跟踪 |
down |
向下移动堆栈跟踪 |
内存(Memory)
| 命令 | 描述 |
|---|---|
info proc mappings |
列出内存映射 |
info proc status |
列出内存状态 |
info files |
列出文件 |
线程(Threads)
| 命令 | 描述 |
|---|---|
info threads |
列出所有线程 |
thread <thread_number> |
选择特定线程 |
命令(Commands)
| 命令 | 描述 |
|---|---|
commands |
列出在断点命中时运行的命令 |
commands <breakpoint_number> |
列出在特定断点命中时运行的命令 |
commands <breakpoint_number> <command> |
添加在特定断点命中时运行的命令 |
end |
结束命令列表 |
杂项(Miscellaneous)
| 命令 | 描述 |
|---|---|
quit 或 q |
退出 GDB |
help 或 h |
列出所有命令 |
help <command> |
显示特定命令的帮助信息 |
进阶
如果你已经尝试了命令行版的 GDB,你或许会觉得这是个反人类的工具。但是它的设计蕴含着它的用途。下面,我们将介绍 GDB 的进阶用法。
汇编调试
汇编调试包含两种情况,编译型语言在某些情况下只有汇编调试才能解决问题,以及无源码的情况下进行 RE。本实验旨在帮助同学们接触了解汇编调试,不会深入讲解。
编译过程
编译型程序,以 C 语言为例,有如下的编译过程,以 1.c
为例:
这里只是以 gcc (GNU Compiler Collection)
的编译过程为例,其他编译器的过程类似。
1 |
|
1 | gcc -g -o 1 1.c |
它的编译过程如下:
- 预处理:
gcc -E 1.c -o 1.i。-E选项表示只进行预处理,不进行编译。此步骤会将#include的头文件内容插入到源文件中,将宏展开,将注释去除等。1.i是个很大的文件,其中main函数的内容如下:
1 | ... |
- 编译:
gcc -S 1.i -o 1.s。此步骤会将 C 语言源代码编译成汇编代码。1.s文件内容如下:
1 | .file "1.c" |
- 汇编:
gcc -c 1.s -o 1.o。这将汇编代码编译成目标文件。1.o是目标文件,可以被链接器链接成可执行文件。 - 链接:
gcc 1.o -o 1。这将目标文件链接成可执行文件。
.so 与链接
.so 与链接.so 文件是共享库文件(Shared Object),在 Linux
系统中用于动态链接。动态链接的优点是可以减少可执行文件的大小,并且多个程序可以共享同一个库文件,从而节省内存。
.so 文件是二进制文件,在编译时,可以使用
-shared 选项生成共享库文件。例如:
1 | gcc -shared -o libexample.so example.c |
在链接时,可以使用 -l 选项链接共享库文件。例如:
1 | gcc -o program program.c -L. -lexample |
其中,-L.
表示在当前目录下查找库文件,-lexample 表示链接
libexample.so 文件。
在运行时,需要设置 LD_LIBRARY_PATH
环境变量,以便系统能够找到共享库文件。例如:
1 | export LD_LIBRARY_PATH=.:$LD_LIBRARY_PATH |
这样,系统就可以在当前目录下查找共享库文件。
寄存器
汇编代码是机器码的助记符表示,是机器码的文本形式。即,计算机执行程序时,会按照汇编代码的指令执行。
要完成实验内容,我们需要知道:
- 指令由 CPU 执行。
- CPU 内部有寄存器,现在的 CPU 寄存器有 64 位(64 bits)。
- 寄存器的速度很快(1ns),比内存快很多(100-150ns)。
本次我们只介绍 x86 和 x86-64(x64) 的汇编代码,即 Intel 汇编代码。为方便后续漏洞的实验,使用的是 Intel 风格语法。
寄存器分为这样几种:
- 通用寄存器。名如
rax、rbx、rcx、rdx、rsi、rdi、rbp、rsp。 - 标志寄存器。名如
ZF、SF、OF、CF、PF。它们只有 1 位,用于标志运算结果,均位于rflags寄存器中。 - 指令寄存器,为
rip,用于存储下一条指令的地址。 - ……
rax (64 位)是从 eax (32
位)继承而来的,eax 是从 ax (16
位)继承而来的,ax 是从 ah 和 al
(8 位)继承而来的。如图所示:
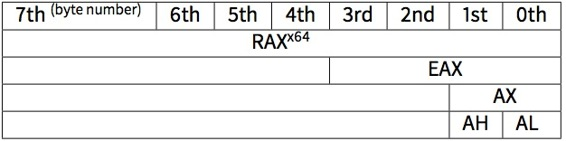
其他寄存器也是类似的命名规则。
Objdump
objdump 用于给出目标文件的汇编代码。此脚本将编译
.c 文件并给出汇编代码。
1 |
|
创建文件后,使用 chmod +x see_amd64.sh
添加执行权限。
汇编入门
程序栈
栈是一种数据结构,它是一种先进后出(First In Last Out)的数据结构。栈的特点是只能在栈顶进行操作,即只能在栈顶压入数据和弹出数据。你可以想像它是一个薯片筒,你只能在筒口放入薯片和取出薯片,不能对中间的薯片进行操作。
程序栈是程序运行时的栈,用于存储函数的局部变量、函数的参数、函数的返回地址等。程序栈是由操作系统分配的,每个线程都有自己的程序栈。
程序栈的大小根据操作系统和编译器而不同。若空间用尽,程序栈溢出,会导致程序崩溃。
空函数
1 | int return_13754() |
其对应的汇编代码可以精简成这样,尽管并不能正常运行:
1 | main: |
1 | 0000000000001040 <main>: |
eax 通常用于存储累加结果,并存储函数返回值。
xor eax, eax 是将 eax
寄存器的值与自己进行异或操作,结果为 0,即将 eax
寄存器清零。 ret 是函数返回指令,它会将栈顶的地址弹出到
rip 寄存器中,即返回到调用函数的下一条指令。
mov (move)
命令名字带有误解性,它实际上是将右边的值赋给左边的寄存器。mov eax, 0x35ba
是将 0x35ba 赋给 eax 寄存器。
1 | 0000000000001129 <return_13754>: |
endbr 是一种程序保护机制使用的指令,我们不必理会。
这段代码包括了程序函数的基本结构,序言和尾声。
1 | push %rbp ; 保存调用者的栈帧 |
push 是将寄存器的值压入栈中,pop
是将栈顶的值弹出到寄存器中。rbp
是基址指针,用于指向当前栈帧的基址。rsp
是栈指针,用于指向当前栈顶。经过序言,原函数的栈低被保存,新函数的栈顶与栈底被设置。
1 | pop %rbp ; 恢复调用者的栈帧 |
ret 是函数返回指令,它会将栈顶的地址弹出到
rip 寄存器中,即返回到调用函数的下一条指令。
这个过程的栈看上去会是这样的: 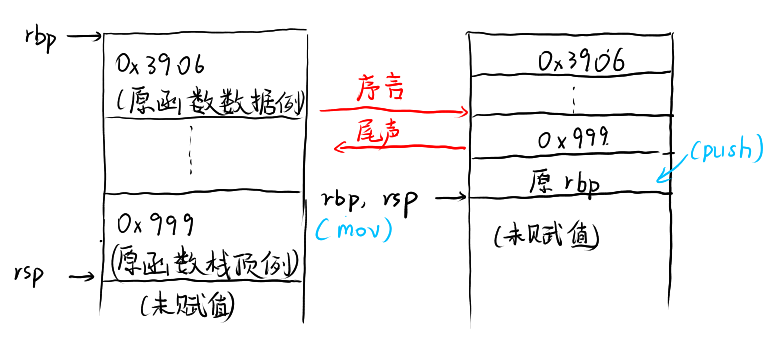
在执行到尾声前,程序栈一定会返回右侧栈状态,否则将会发生段错误。
参数传递
1 | int add(int a, int b) |
1 | 0000000000001129 <add>: |
DWORD 是双字,即 4 字节。DWORD PTR 表示指向
4 字节的指针。[rbp-0x4] 表示 rbp
寄存器的值减去
0x4,即栈中的第一个参数。[rbp-0x8]
表示栈中的第二个参数(int 类型占 4 字节)。edi
和 esi 是通用寄存器,用于存储函数的参数。
edi 和 esi 分别存储了 1 和
2,随后进入 add 函数,edi 和
esi 被存入 DWORD PTR [rbp-0x4] 和
DWORD PTR [rbp-0x8],即 a 和
b,进行加法运算后返回。
如图所示: 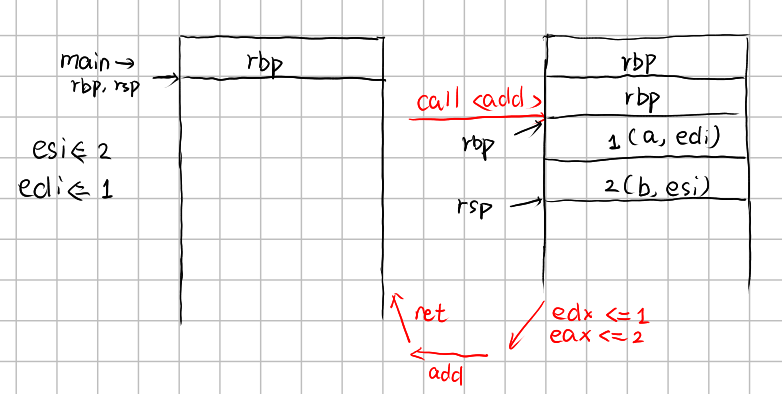
通常,参数传递是通过寄存器传递的,但是当参数过多时,会通过栈传递,即先将参数压入栈中,再进行函数调用,函数内部再将参数读取出来。
局部变量
1 | int add(int a, int b) |
1 | 0000000000001129 <add>: |
DWORD PTR [rbp-0x14] 和
DWORD PTR [rbp-0x18] 分别存储了 a 和
b 的值,DWORD PTR [rbp-0x4] 存储了
c 的值。[rbp-0x14] 和 [rbp-0x18]
是 a 和 b 的存储位置,[rbp-0x4]
是 c 的存储位置。
条件语句
1 | int max(int a, int b) |
1 | 0000000000001129 <max>: |
我们先来详细介绍下 rflags 寄存器。它的结构如图所示:
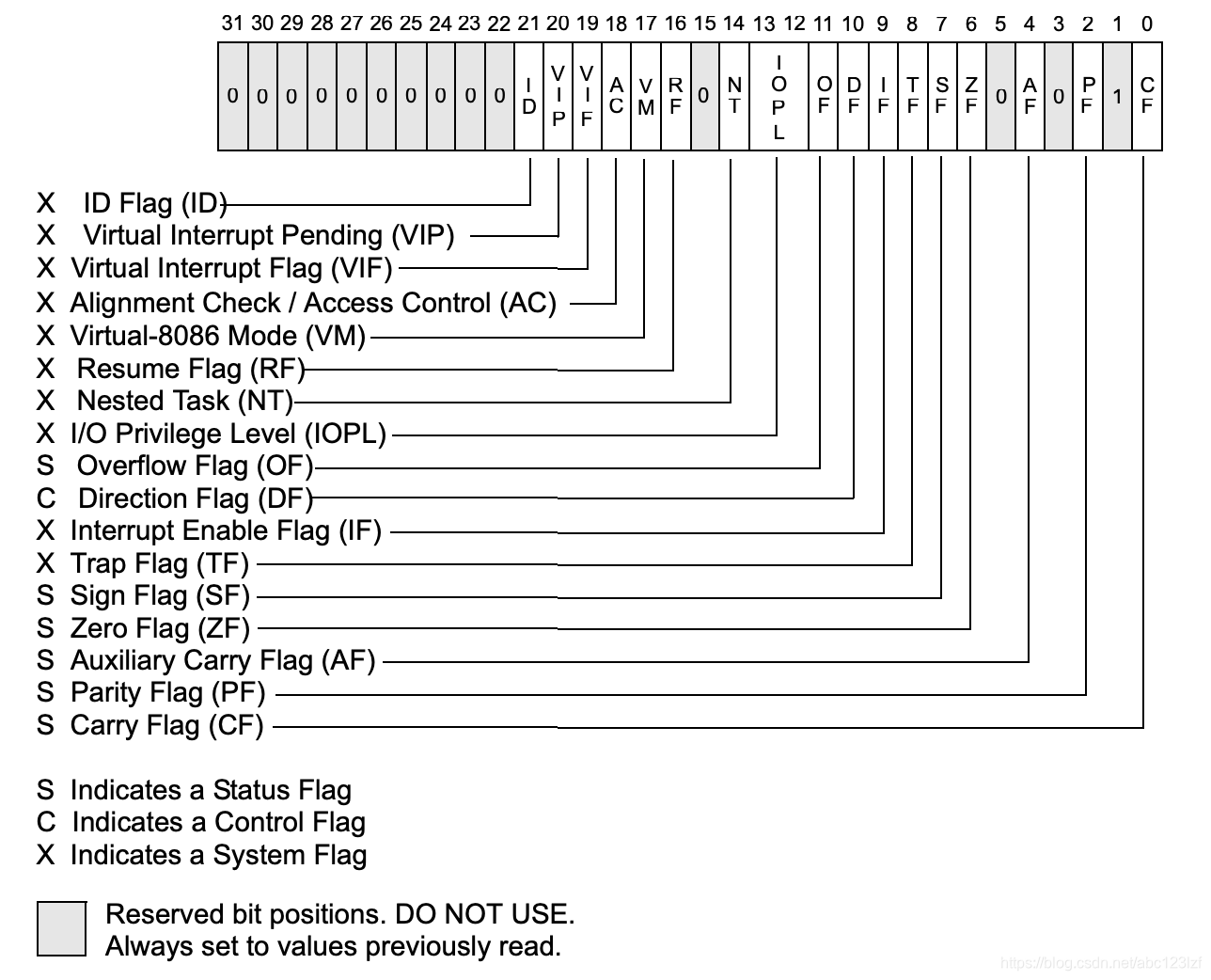
(这实际上是 eflags 寄存器,rflags 的高 32
位现在还没有设计用途)。它的每一位都有特定的含义,并且可以通过
set 和 clear 指令设置和清除。通常,这此位是由
CPU 指令设置的。例如,cmp (compare)
指令会将两个操作数相减(不影响寄存器的值),并根据结果设置
ZF、SF、OF、CF
等位(设指令为 cmp a, b):
- 无符号时:
ZF(zero flag) 为 1 表示两个操作数相等。CF(carry flag) 为 1 表示无符号数相减时发生了借位或错位,相减只能是借位,即a < b。ZF、CF均为0,则a > b。
- 有符号时:
SF(sign flag) 为 1 表示结果为负数,OF(overflow flag) 为 1 表示发生了溢出。两者均为 1, 则a < b(a为负数,b为正数)。SF、OF均为0,则a > b。SF为 1,OF为 0,a < b。SF为 0,OF为 1,a > b。
jle (jump if less or equal) 指令会根据 ZF
和 SF 位的值跳转。类似的命令还有 jl (jump if
less)、jg (jump if greater)、jge (jump if
greater or equal) 等。
这样,我们就有了条件语句的实现。
循环语句
1 | int sum(int n) |
1 | 0000000000001129 <sum>: |
小端序与大端序
在计算机中,数据的存储方式有两种:小端序(Little Endian)和大端序(Big Endian)。小端序是指低位字节存储在低地址,高位字节存储在高地址;大端序是指高位字节存储在低地址,低位字节存储在高地址。换句话说,大端序是人类大多数语言的从左到右的读写方式,而小端序反之。
是的,这是一个没有用的图片,并且它实际上没解释任何东西,我只是觉得这个地方应该有张图片。
尽管大端序对人类更友好,但小端序有其独特优势。例如,若你想要计算
0x12345678 + 0x12345678,若是大端序,读取顺序为
0x12、0x34、0x56、0x78,然后从
0x78 向前进行运算;而对于小端序,其存储顺序为
0x78、0x56、0x34、0x12,从
0x78
向后进行运算,这样就可以直接进行加法运算,而不需要进行进位操作。
在 x86 架构中,是小端序存储的,字符串的存储方式也是小端序的,例如:
1 |
|
1 | 0000000000001169 <main>: |
mov rax,QWORD PTR fs:0x28
是一种程序保护机制,我们可以先忽略它。movabs
是将立即数赋给寄存器,在这里,你可以把它当作 mov
解读。lea 是将地址赋给寄存器,rdi
是函数参数寄存器,call 是函数调用指令。
这里,我们触发了函数使用栈传递参数的情况,rdi
寄存器存储了字符串的地址,puts
函数会输出字符串。0x6f77206f6c6c6548 对应于字符串
ow olleH,0x2e646c726f7720 对应于字符串
.dlrow。
IDA Pro
IDA(Interactive Disassembler)是一款反汇编工具,它可以将二进制文件反汇编成汇编代码,由 Hex-Rays 公司开发。IDA Pro 是其商业版本,支持商业许可、Python 脚本等功能。
IDA 普通版包括了我们本次实验的需要的所有功能,但还是提供 Pro
版本。要激活,请在其安装文件夹下运行提供的 keygen2.py
即可。
其单键快捷键有些混乱,如下:
CCodeDDataNRenameUUndefineAStringXXrefsRCharactorSSegment
GDB 拓展
这里想要介绍一些 GDB 的拓展功能,包括 GDB 脚本、GDB Python、GDB 插件。
GDB 脚本
GDB
支持脚本拓展,虽然原生语法并不太友好,但至少可以实现一些简单的功能。脚本文件以
.gdb 结尾。
1 | file a.out |
脚本运行方法为 gdb -x script.gdb,-x
选项表示执行脚本。也可以先启动 GDB,然后在 GDB 命令行中使用
source script.gdb 命令。
若你有兴趣可以自行查阅文档写带条件或循环的脚本,不过感觉没什么必要,因为 GDB 的语法非常特殊,不类似任何一种语言(稍微有点像 bash)。此外,参数是通过文本替换来处理的,这意味着处理包含空格或特殊字符的参数会非常困难(甚至不可能)。
用户定义命令
以下内容译自 GDB 官方文档 23.3.1 节:
用户定义命令是将一系列 GDB 命令赋予一个新名称作为命令。这是通过
define 命令完成的。
用户命令可以接受任意数量的由空格分隔的参数。在用户命令中通过
$arg0...$argN
访问参数。参数是文本替换的,因此它们可以引用变量、使用复杂表达式,甚至执行被调试程序的函数调用。然而,这种文本替换意味着处理某些参数会比较困难。例如,用户无法传递包含空格的参数;而将参数字符串化可以使用类似
"$arg1"
的表达式,但如果参数包含引号,这将会失败。对于更复杂和健壮的命令,我们建议使用
Python 编写;参见第 23.3.2.21 节 [Python 中的 CLI 命令],第 463 页。
一个简单的例子:
1 | define adder |
要执行该命令,使用:
1 | adder 1 2 3 |
这定义了命令 adder,它打印其三个参数的和。
此外,$argc 可以用来确定传递了多少参数。
1 | define adder |
结合 eval 命令(参见 [eval],第 398
页)可以更容易地处理可变数量的参数:
1 | define adder |
GDB Python
我们可以通过 Python 脚本扩展 GDB 的功能,例如自动化调试、自定义命令等。这里,我们只是简单介绍一下基础用法。
基础用法
1 | gdb -q -x script.py |
-q 选项表示静默模式,不显示 GDB
的启动信息。-x 选项表示执行脚本。
或者在 GDB 命令行中使用 source script.py 命令。
1 | import gdb |
import gdb 导入 GDB 模块。gdb.execute
函数用于执行 GDB 命令。类似地,我们可以用 gdb.execute 完成
GDB 动态调试的自动化。
自动化测试
例如,我们可能会注意到自己的程序在某些情况下会崩溃退出,想要找到崩溃的输入。我们可以通过 Python 脚本自动化这个过程。
1 |
|
1 | import gdb |
多线程
以下内容译自 GDB 官方文档 23.3.2.2 节:
GDB 并不是线程安全的。如果你的 Python 程序使用了多个线程,你必须小心,只能在 GDB 线程中调用 GDB 特定的函数。GDB 提供了一些函数来帮助处理这个问题。
gdb.block_signals() [函数]
如前所述(参见第 23.3.2.1 节 [Basic Python]),某些信号必须传递给 GDB
主线程。block_signals
函数返回一个上下文管理器,该管理器将在进入时阻塞这些信号。这可以在启动新线程时使用,以确保信号在新线程中被阻塞,例如:
1 | with gdb.block_signals(): |
gdb.Thread [类]
这是 Python 的 threading.Thread 类的子类。它重写了
start 方法,以调用 block_signals,使其成为在
GDB 中创建线程的易用替代品。
gdb.interrupt() [函数]
这会使 GDB 反应,就像用户在终端输入了一个 control-C
字符一样。也就是说,如果被调试程序正在运行,它会被中断;如果 GDB
命令正在执行,它会被停止;如果 Python 命令正在运行,会引发
KeyboardInterrupt。与 GDB 中的大多数 Python API
不同,interrupt 是线程安全的。
gdb.post_event(event) [函数]
将 event(一个不带参数的可调用对象)放入 GDB
的内部事件队列。这个可调用对象将在稍后的某个时间点,在 GDB
的事件处理过程中被调用。使用 post_event
发布的事件将按发布的顺序运行;然而,无法知道它们相对于 GDB
内部的其他事件何时被处理。
与 GDB 中的大多数 Python API 不同,post_event
是线程安全的。例如:
1 | (gdb) python |
这个示例展示了如何使用 gdb.post_event
在多线程环境中安全地调用 GDB 函数。
以下是例子: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42import gdb
import string
import itertools
import threading
# 测试函数
def test_input(charset, length, start, end):
for candidate in itertools.product(charset, repeat=length):
test_input = ''.join(candidate)
print(f"\033[92mTesting input: {test_input}\033[0m", end='\r')
gdb.execute(f"run < <(echo {test_input})", to_string=True)
if "SIGSEGV" in gdb.execute("bt", to_string=True):
print(f"\033[91mCrash found with input: {test_input}\033[0m")
return
gdb.execute("kill")
def main():
gdb.execute("file crash")
gdb.execute("set disable-randomization on") # 关闭 ASLR,这样每次运行程序的地址都是固定的
gdb.execute("b handle_request")
gdb.execute("b *0x00005555555553c7")
# 我们想要测试的字符集
charset = string.ascii_letters + string.digits # 可以根据实际情况修改
print(charset)
# 创建线程
threads = []
num_threads = 4 # 线程数量,可以根据需要调整
for length in range(1, 101): # 假设最大输入长度为 100
for i in range(num_threads):
start = i * (len(charset) // num_threads)
end = (i + 1) * (len(charset) // num_threads)
thread = threading.Thread(target=test_input, args=(charset[start:end], length, start, end))
threads.append(thread)
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()
if __name__ == "__main__":
main()
GDB 插件
有不少 GDB 插件可以为 GDB 提供图形化界面、自动化调试等功能,例如 GEF、Pwndbg、gdb-dashboard 等。